感知机算法的收敛性
对于线性可分的数据集,感知机学习算法的原始形式是收敛的。也就是说,经过有限次的迭代,可以找到一个将数据集完全正确划分的分离超平面。
本文是<统计学习方法>第二章感知机收敛性证明的笔记,主要加入了一点自己的理解。
在证明之前,先定义下相关的符号标记。
- 将参数b并入权重向量w,记作
$$\hat{w} = (w^T, b)^T$$
- 将输入向量加进常数 1,记作
$$\hat{x} = (x^T, 1)^T$$
很显然,向量内积 $\hat{w} \cdot \hat{x} = w \cdot x + b$
收敛性证明
Novikoff 定理

式(2.8)证明
由于训练数据集是线性可分的,存在超平面将训练数据集完全正确分开,取此超平面为
$$
\hat{w}_{opt} \cdot \hat{x} = (w_{opt}^T, b_{opt})^T \cdot (x^T, 1)^T = w_{opt} \cdot x + b_{opt} = 0
$$
使$||\hat{w}_{opt}|| = 1$。由于样本均分类正确,所以对所有的样本,均满足
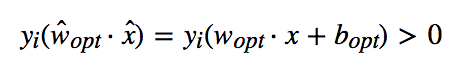
因此可以从所有样本中找到一个最小取值,使得
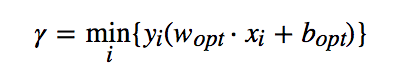
样本中所有数据均满足
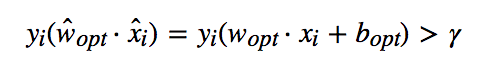
式(2.9)证明
感知机算法中,如果实例被误分类,则更新权重。令 $\hat{w}_{k-1}$ 是第 $k$ 个误分类实例之前的扩充权重向量,即
$$
\hat{w}_{k-1} = (w_{k-1}^T, b_{k-1})^T
$$
则对于第 k 个误分类实例,它的误分类判断条件为
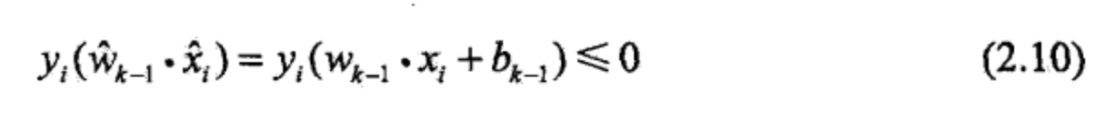
若$(x_i, y_i)$是被$\hat{w}_{k-1} = (w_{k-1}^T, b_{k-1})^T$误分类的数据,则w和b的更新规则是
$$
\begin{align}
w_k &\leftarrow w_{k-1} + \eta y_i x_i \\
b_k &\leftarrow b_{k-1} + \eta y_i
\end{align}
$$
即

下面推导两个不等式
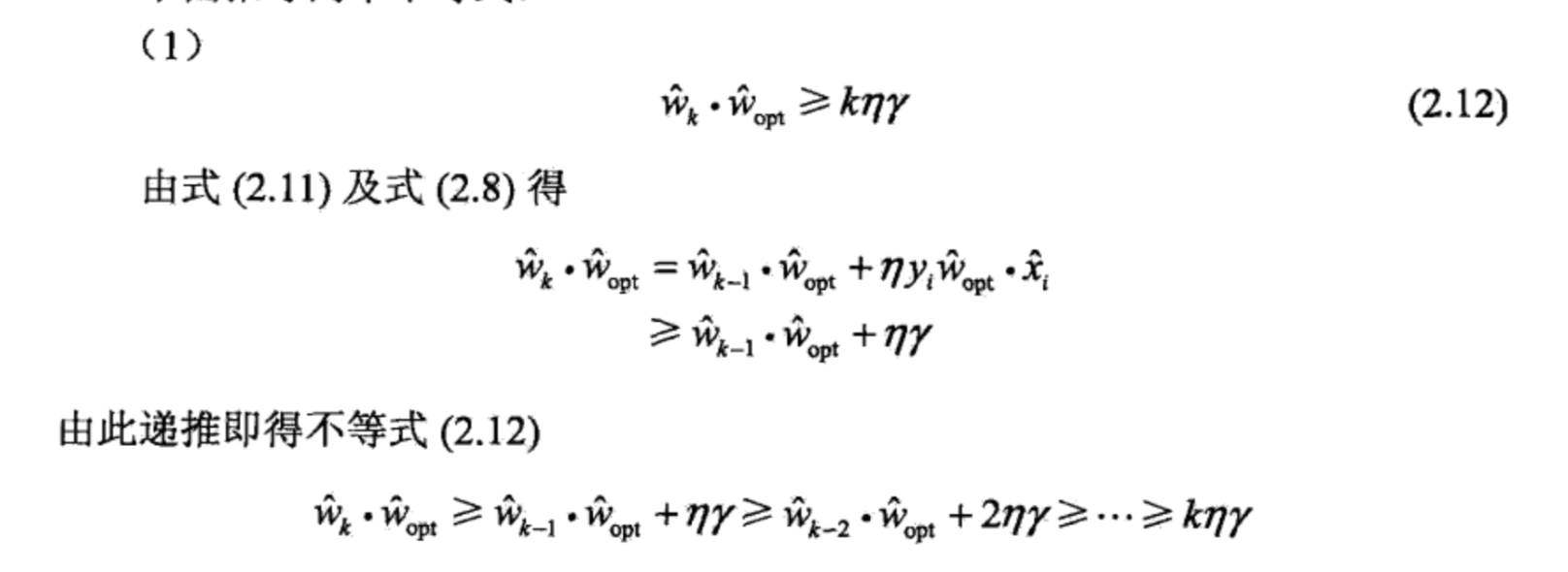
其中第二步用到了式(2.8)
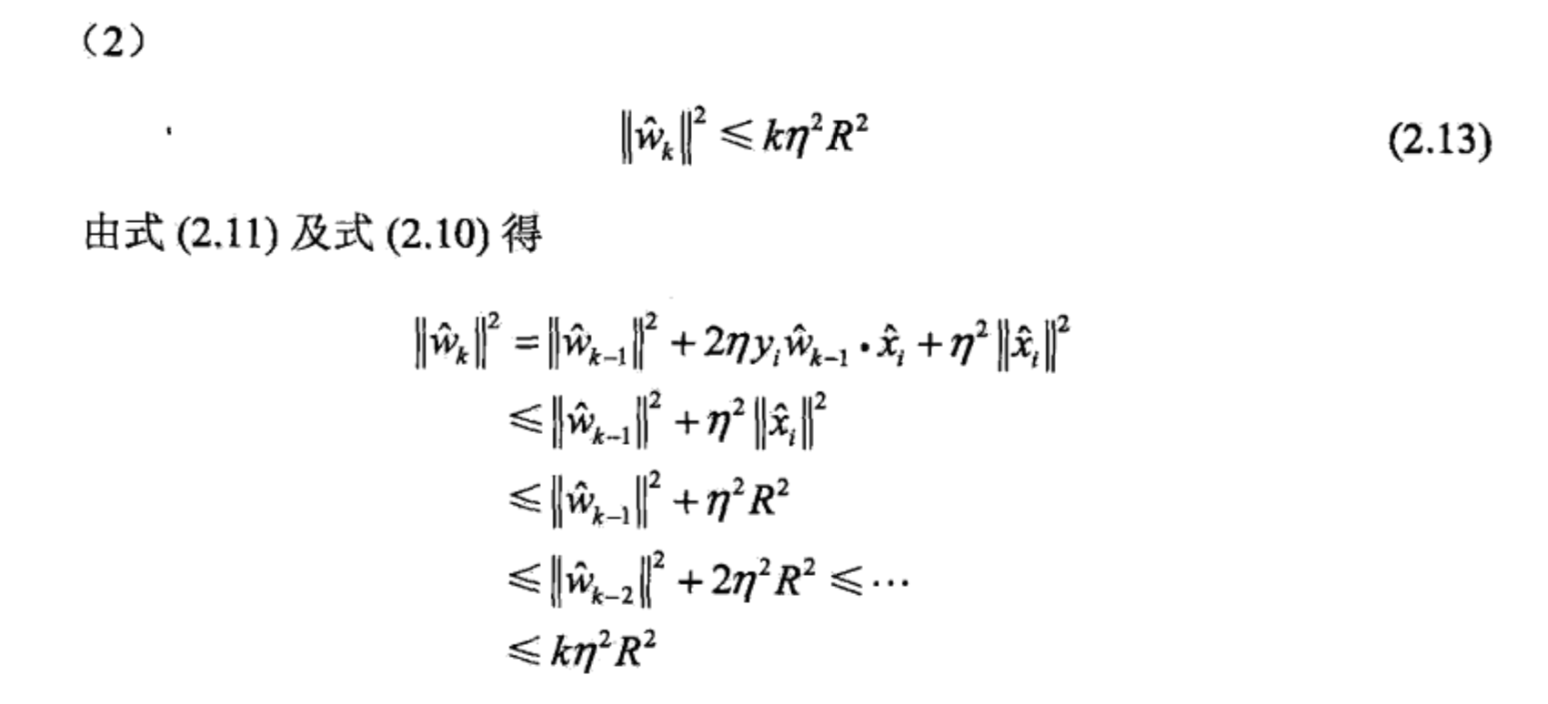
其中第一步用到了$||y_i||=1$(因为$y_1$的取值范围为-1或1),第二步用到了式(2.10),第三步用到了$R$的定义,第四步及之后用到了数学归纳法
结合不等式(2.12)和(2.13)可得
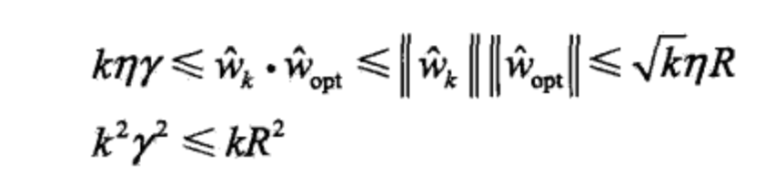
首先看下第一个不等式,其中第一步就是(2.12),第二步用到了施瓦茨不等式,第三步用到了(2.13)和证明一的条件$||\hat{w}_{opt}|| = 1$
再看第二个不等式,对第一个不等式两侧取平方可得
因此可得
$$
k \leq (\frac{R}{\gamma})^2
$$
参考
李航. 统计学习方法
- 2018-08-04
感知机算法是<统计学习方法>这本书讲的第一个机器学习算法,据说是最简单的机器学习算法。这里参考书中的例子,使用程序实现该算法,以便加深理解。
- 2018-07-19
本节首先介绍函数间隔和几何间隔的概念,进而引出最优间隔分类器和拉格朗日对偶,最后介绍核函数和SMO algorithm
- 2018-07-08
前两节分别介绍了一个回归模型和一个分类模型,其中线性回归中假设概率分布为 $y|x;\theta \sim N(\mu, \sigma^2)$,二分类中假设概率分布为 $y|x;\theta \sim Bernoulli(\phi)$。这两种模型都是广义线性模型(Generalized Linear Models)的特殊情况。
- 2018-07-14
前面讲到的学习算法都是对 $p(y|x;\theta)$ 建模。例如逻辑回归算法对 $p(y|x;\theta)$ 建模得到 $h_\theta(x)=g(\theta^Tx)$ (其中g是sigmoid函数),直观上可以理解为:找到一条直线,将数据集划分为$y=1$和$y=0$两种,对新的输入,根据结果落在直线的哪一侧预测为对应的分类。这种叫做判别学习算法
- 2018-07-07
二分类(binary classification)是最简单的一种分类问题,$y$ 的取值只有两种:0和1,对应的样本分别称为负样本和正样本。逻辑回归(Logistic regression)可用于处理二分类问题。