cs229笔记2:逻辑回归
二分类(binary classification)是最简单的一种分类问题,$y$ 的取值只有两种:0和1,对应的样本分别称为负样本和正样本。逻辑回归(Logistic regression)可用于处理二分类问题。
逻辑回归
定义 $h_\theta(x)$
$$
h_\theta(x) = g(\theta^Tx) = \frac{1}{1 + e^{-\theta^Tx}}
$$
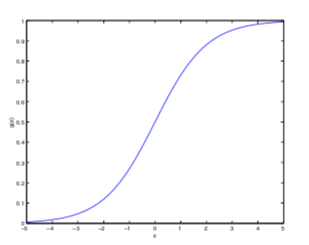
其中用到了 sigmoid function
$$
g(z) = \frac{1}{1 + e^{-z}}
$$
当$z$趋于$+\infty$时$g(z)$趋于1;当$z$趋于$-\infty$时$g(z)$趋于0
对其求导得到
$$
\begin{align}
{g}’(z) &= \frac{d}{dz} \frac{1}{1 + e^{-z}} \\
&= \frac{1}{(1 + e^{-z})^2}(e^{(-z)}) \\
&= \frac{1}{(1 + e^{-z})} (1 - \frac{1}{(1 + e^{-z})}) \\
&= g(z)(1 - g(z))
\end{align}
$$
假设概率如下
$$p(y = 1 | x; \theta) = h_\theta(x)$$
$$p(y = 0 | x; \theta) = 1- h_\theta(x)$$
则可以统一表示为
$$p(y | x; \theta) = (h_\theta(x))^y (1- h_\theta(x))^{(1-y)}$$
似然函数如下
$$
\begin{align}
L(\theta) &= p(\vec{y}|X;\theta) \\
&= \prod_{i=1}^{m}p(y^{(i)}|x^{(i)};\theta) \\
&= \prod_{i=1}^{m}(h_\theta(x^{(i)}))^{(y^{(i)})}(1 - h_\theta(x^{(i)}))^{(1 - y^{(i)})}
\end{align}
$$
同样取对数似然函数
$$
\begin{align}
l(\theta) &= logL(\theta) \\
&= \sum_{i=1}^{m}y^{(i)}log(h(x^{(i)})) + (1 - y^{(i)})log(1 - h(x^{(i)}))
\end{align}
$$
假设只有一个样本$(x,y)$,根据梯度上升法$\theta := \theta + \alpha\bigtriangledown_\theta l(\theta)$,首先对 $\theta$ 求偏导得到梯度
$$
\begin{align}
\frac{\partial}{\partial \theta_j}l(\theta)
&= (y\frac{1}{g(\theta^Tx)} - (1-y)\frac{1}{1-g(\theta^Tx)})\frac{\partial}{\partial \theta_j}g(\theta^Tx) \\
&= (y\frac{1}{g(\theta^Tx)} - (1-y)\frac{1}{1-g(\theta^Tx)})g(\theta^Tx)(1-g(\theta^Tx))\frac{\partial}{\partial \theta_j}\theta^Tx \\
&= (y(1-g(\theta^Tx)) - (1-y)g(\theta^Tx))x_j \\
&= (y-h_\theta(x))x_j
\end{align}
$$
代入公式得到梯度上升更新规则,注意这里为了使$L(\theta)$取到最大值,使用的是梯度上升
$$
\theta_j := \theta_j + \alpha(y^{(i)} - h_\theta(x^{(i)})x_j^{(i)}
$$
感知机
如果逻辑回归的 $g(z)$ 改为如下函数
$$
g(z) = \begin{cases}
1 & \text{ if } z \geqslant 0 \\
0 & \text{ if } z < 0
\end{cases}
$$
这样可以得到感知机学习算法(perceptron learning algorithm)
牛顿方法
考虑另外一个最小化 $J(\theta)$ 的方法,牛顿方法使用了另外一种思路,它的更新规则如下
$$
\theta := \theta - \frac{f(\theta)}{f’(\theta)}
$$
如下图所示,选曲线上一点画出切线,则 $f(\theta)$ 表示该点的纵坐标,$f’(\theta)$ 表示三角形中纵向长度与横向长度(注意是在$f(x)=0$这条线上)的比值,因此 $\frac{f(\theta)}{f’(\theta)}$ 表示三角形横向长度。上述式子相当于每次把 $\theta$ 减少三角形横向长度。迭代数次后可以找到一个 $\theta$ 使得 $f(\theta)=0$。
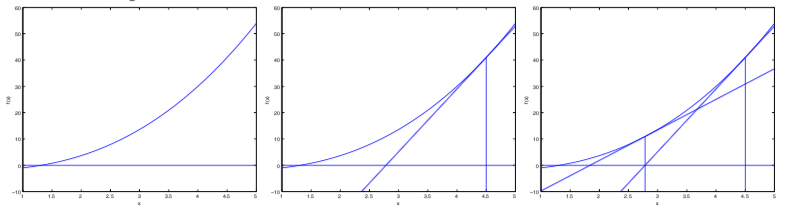
考虑另一个问题:如何最大化 $l(\theta)$?当其取最大值时 $l’(\theta)=0$,我们只需要找到使该一阶导数为0的点,可将其代入上述公式,进而得到如下公式
$$
\theta := \theta - \frac{f’(\theta)}{f’’(\theta)}
$$
- 2018-07-05
俗话说好记性不如烂笔头,看过的东西很快就会忘了,记录下来一方面会增强记忆,另一方面也方便查阅。这里根据css229视频和讲义简单做下笔记。
- 2018-07-08
前两节分别介绍了一个回归模型和一个分类模型,其中线性回归中假设概率分布为 $y|x;\theta \sim N(\mu, \sigma^2)$,二分类中假设概率分布为 $y|x;\theta \sim Bernoulli(\phi)$。这两种模型都是广义线性模型(Generalized Linear Models)的特殊情况。
- 2018-07-19
本节首先介绍函数间隔和几何间隔的概念,进而引出最优间隔分类器和拉格朗日对偶,最后介绍核函数和SMO algorithm
- 2018-07-14
前面讲到的学习算法都是对 $p(y|x;\theta)$ 建模。例如逻辑回归算法对 $p(y|x;\theta)$ 建模得到 $h_\theta(x)=g(\theta^Tx)$ (其中g是sigmoid函数),直观上可以理解为:找到一条直线,将数据集划分为$y=1$和$y=0$两种,对新的输入,根据结果落在直线的哪一侧预测为对应的分类。这种叫做判别学习算法
- 2018-08-04
感知机算法是<统计学习方法>这本书讲的第一个机器学习算法,据说是最简单的机器学习算法。这里参考书中的例子,使用程序实现该算法,以便加深理解。