cs229笔记3:广义线性模型
前两节分别介绍了一个回归模型和一个分类模型,其中线性回归中假设概率分布为 $y|x;\theta \sim N(\mu, \sigma^2)$,二分类中假设概率分布为 $y|x;\theta \sim Bernoulli(\phi)$。这两种模型都是广义线性模型(Generalized Linear Models)的特殊情况。
指数分布族
在讲广义线性模型之前先介绍下指数族分布,指数族分布是指概率分布可以写如下形式的分布
$$
p(y;\eta) = b(y) exp(\eta^T T(y) - a(\eta))
$$
其中 $\eta$ 是自然参数(natural parameter),也可以叫做canonical parameter 。$T(y)$ 是充分统计量(sufficient statistic),$a(\eta)$ 是 log partition function。$e^{-a(\eta)}$ 是归一化常量
给定 T、a、b的定义,可以得到一族以$\eta$为参数的分布,变化$\eta$的值可以得到不同的分布
伯努利分布
均值为$\phi$的伯努利分布记为: $Bernoulli(\phi)$,满足$y \in (0,1)$。变化$\phi$的取值可以得到不同均值的分布。
$$
\begin{align}
p(y=1;\phi) &= \phi \\
p(y=0;\phi) &= 1-\phi
\end{align}
$$
可以将其概率写成如下形式
$$
\begin{align}
p(y;\phi) &= \phi^y (1-\phi)^{(1-y)} \\
&= exp(ylog\phi + (1-y)log(1-\phi)) \\
&= exp((log\frac{\phi}{1-\phi})y + log(1-\phi))
\end{align}
$$
令自然参数 $\eta = log\frac{\phi}{1-\phi}$,如果对$\phi$求解可以得到$\phi = \frac{1}{1+e^{-\eta}}$。对照指数族分布的形式可以得到T、a、b如下
$$T(y) = y$$
$$
\begin{align}
a(\eta) &= -log(1-\phi) \\
&= log(1+e^{\eta})
\end{align}
$$
$$b(y) = 1$$
高斯分布
根据之前线性回归 概率解释 的推导过程可知,$\sigma^2$不影响$\theta$和$h(\theta)$的选择。为简化推导过程,这里令$\sigma^2=1$,因此可得
$$
\begin{align}
p(y;\mu) &=\frac{1}{\sqrt{2\pi}} exp(-\frac{1}{2}(y-\mu)^2) \\
&= \frac{1}{\sqrt{2\pi}} exp(-\frac{1}{2}y^2) \cdot exp(\mu y - \frac{1}{2} \mu^2)
\end{align}
$$
令T、a、b、$\eta$如下
$$\eta = \mu$$
$$T(y) = y$$
$$a(\eta) = \frac{\mu^2}{2} = \frac{\eta^2}{2}$$
$$b(y) = \frac{1}{\sqrt{2\pi}} exp(-\frac{y^2}{2})$$
还有很多其他的分布也属于指数族分布,比如多项式分布、泊松分布、伽马分布、指数分布、beta 分布、Dirichlet 分布等
构造 GLMs
广义线性模型基于指数族分布。为了构造广义线性模型,首先给出关于条件概率分布 $y|x$ 的3个假设
$y|x;\theta \sim ExponentialFamily(\eta)$。给定 $x、\theta$,$y$ 服从参数为 $\eta$ 的指数族分布
给定 $x$,目标是输出 $T(y)$ 的期望值($E[T(y)|x]$),也就是学习算法的输出 $h(x) = E[T(y)|x]$。在之前的例子中,$T(y) = y$,所以上式为 $h(x) = E[y|x]$。比如在逻辑回归中 $h_\theta(x) = p(y=1|x;\theta) = 0 \cdot p(y=0|x;\theta) + 1 \cdot p(y=1|x;\theta) = E[y|x;\theta]$
自然参数 $\eta$ 和输入变量 $x$ 是线性关系:$\eta = \theta^Tx$ (如果 $\eta$ 是向量,则 $\eta_i = \theta_i^Tx$)
最小二乘法
最小二乘法(Ordinary Least Squares)是GLM的一种特殊情况。目标变量$y$是连续的,对$y|x$使用高斯分布建模,即 $y|x \sim N(\mu,\sigma^2)$。根据之前的推导可知
$$y|x;\theta \sim ExpFamily(\eta)$$
根据假设
$$
\begin{align}
h_\theta(x) &= E[y|x;\theta] \\
&= \mu \\
&= \eta \\
&= \theta^x
\end{align}
$$
逻辑回归
目标变量取值范围为 $y\in(0,1)$,对$y|x$使用伯努利分布建模,推导如下
$$
\begin{align}
h_\theta(x) &= E[y|x;\theta] \\
&= \phi \\
&= \frac{1}{1+e^{-\eta}} \\
&= \frac{1}{1+e^{-\theta^Tx}}
\end{align}
$$
引入 $g(\eta) = E[T(y);\eta]$,它叫做 canonical response function,而 $g^{(-1)}$ 称为 canonical link function
Softmax Regression
假设分类问题中,输出变量 $y$ 的取值范围为 $1,2,…,k$,考虑使用多项分布对其建模。首先将多项分布表示为指数族分布
使用 k 个参数$\phi_1,…,\phi_i$ 表示取到每个值的概率。因为总的概率为1($\sum_{i=1}^{k} \phi_i = 1$),所以可以使用 k-1 个参数来表示多项分布。其中前 k-1 个参数表示为 $\phi_i = p(y=i;\phi)$,第 k 个参数表示为 $p(y=k;\phi) = 1 - \sum_{i=1}^{k-1}\phi_i$。
定义 $T(y) \in \mathbb{R}^{(k-1)}$ 如下
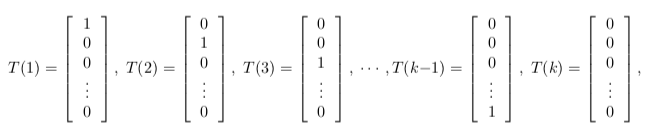
引入指示函数 I{.},如果括号内取值为 True 则结果为 1 (I{True} = 1),否则结果为 0 (I{False} = 0)。T(y)和y之间的关系可以表示为
$$(T(y))_i = I{y=i}$$
因此$E[(T(y))_i] = p(y=i) = \phi_i$。将多项分布表示为指数族分布
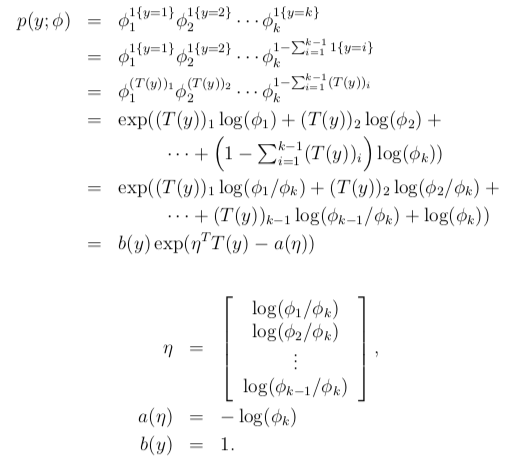
link function 可表示为
$$\eta_i = log\frac{\phi_i}{\phi_k}$$
为方便表示,定义
$$\eta_k = log\frac{\phi_k}{\phi_k} = 0$$
可以得到
$$
\begin{align}
e^{\eta_i} &= \frac{\phi_i}{\phi_k} \\
\phi_k \cdot e^{\eta_i} &= \phi_i \\
\phi_k \cdot \sum_{i=1}^{k} e^{\eta_i} &= \sum_{i=1}^{k} \phi_i = 1
\end{align}
$$
因此 $\phi_k = \frac{1}{\sum_{i=1}^{k} e^{\eta_i}}$,由此可得
$$\phi_i = \frac{e^{\eta_i}}{\sum_{j=1}^{k} e^{\eta_j}}$$
这个函数将 $\eta$ 映射到 $\phi$,称为 softmax function
根据假设3,$\eta_i$ 和 $x$ 线性相关,因此可得 $\eta_i = \theta_i^Tx$ (i=1,…,k-1),其中 $\theta_i,…,\theta_{k-1} \in \mathbb{R}^{n+1}$。为方便表示,定义 $\theta_k=0$,因此 $\eta_k = \theta_k^Tx = 0$
$$
\begin{align}
p(y=i|x;\theta) &= \phi_i \\
&= \frac{e^{\eta_i}}{\sum_{j=1}^{k} e^{\eta_j}} \\
&= \frac{e^{\theta_i^Tx}}{\sum_{j=1}^{k} e^{\theta_j^Tx}}
\end{align}
$$
该模型用于解决多分类问题,叫做 softmax regression,它是逻辑回归的一般化。这里学习函数的输出如下
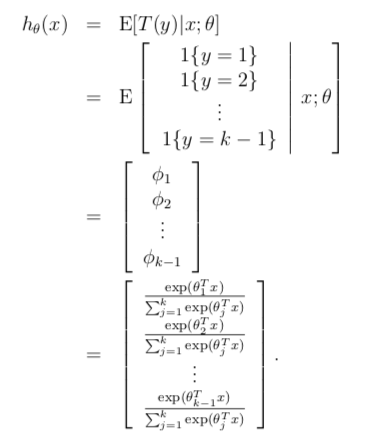
对 $i = 1,…,k$ 的每一个值,这个公式输出对应的 $p(y=i|x;\theta)$ 的预测概率。注意 $p(y=k|x;\theta)$ 可根据前 k-1 个概率得到。
根据以上结论,可以得到 log 似然函数如下。据此可以求出最大似然估计值(可以使用梯度上升或牛顿方法)
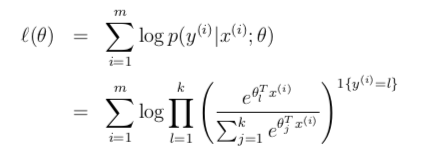
- 2018-07-07
二分类(binary classification)是最简单的一种分类问题,$y$ 的取值只有两种:0和1,对应的样本分别称为负样本和正样本。逻辑回归(Logistic regression)可用于处理二分类问题。
- 2018-07-05
俗话说好记性不如烂笔头,看过的东西很快就会忘了,记录下来一方面会增强记忆,另一方面也方便查阅。这里根据css229视频和讲义简单做下笔记。
- 2018-07-19
本节首先介绍函数间隔和几何间隔的概念,进而引出最优间隔分类器和拉格朗日对偶,最后介绍核函数和SMO algorithm
- 2018-07-14
前面讲到的学习算法都是对 $p(y|x;\theta)$ 建模。例如逻辑回归算法对 $p(y|x;\theta)$ 建模得到 $h_\theta(x)=g(\theta^Tx)$ (其中g是sigmoid函数),直观上可以理解为:找到一条直线,将数据集划分为$y=1$和$y=0$两种,对新的输入,根据结果落在直线的哪一侧预测为对应的分类。这种叫做判别学习算法
- 2018-05-20
升级了 theme-next 主题,开启了 Mathjax 功能,测试下书写公式,先来个看看 $E=mc^2$